
When Networks Fail: Lessons from Recent Outages on Building True Digital Resilience
Network outages used to be contained problems—a cell tower lost power, customers in that area lost service, and technicians restored connectivity within hours. The digital environment has since changed dramatically, with failures now spreading quickly across interconnected systems that society depends on. The April 2024 power grid collapse across Spain and Portugal left tens of millions without mobile service for up to 24 hours. The CrowdStrike incident in July grounded flights, shut down hospitals, and silenced news broadcasts globally. Google Cloud Platform outages cascaded through services like Spotify, taking entire digital ecosystems offline. What changed is not just the scale of these failures, but also how quickly problems spread across interconnected systems essential to economic and social activity.
The root cause lies in digital transformation itself. Organizations have gained tremendous capabilities through cloud services, managed providers, and interconnected networks, but they’ve also created new vulnerabilities. A single software update can now ripple through thousands of companies. A power outage in one region can disable mobile networks across multiple countries. Supply chain dependencies stretch across continents, making it nearly impossible for any single organization to control all the factors that affect their service reliability. Network resilience has shifted from an operational concern to a strategic necessity, as its absence poses systemic risks to entire economies.
In this article, we’ll examine how recent major outages reveal the true nature of network vulnerabilities, explore frameworks that leading operators and policymakers use to build resilience, and show how data from events like the Iberian blackout can guide better preparation strategies. For a deeper look at these topics with real-world examples, watch our recent webinar on-demand, “Navigating Disruption: Best Practices for Resilient Digital Infrastructure.”
What Network Resilience Really Means
Most network operators measure success with basic statistics: how often their networks stay running and how quickly they fix problems when something breaks. Traditional network monitoring focuses on straightforward metrics like uptime (network availability), availability percentages (how often networks stay up), and mean time to repair (how fast problems are solved), but these measurements can miss the bigger picture during major outages.
During major incidents, understanding the true impact requires multiple perspectives that basic statistics like uptime or network availability alone can’t provide. Multiple data sources paint different pictures of the same event, and each tells a key part of the story:
- Consumer reporting platforms like Downdetector® by Ookla® capture user-reported issues but depend on users having working connections to report problems. For a more detailed perspective on how outages impact organizations—and what’s truly at stake when services fail—see our white paper, The Cost of Downtime: A Guide to Proactive Outage Management
- Background network scanning can reveal infrastructure failures but often provides retrospective rather than real-time insights
- Operator dashboards track internal systems but often lack visibility into interdependent infrastructure like power grids
- Government monitoring focuses on critical services like emergency communications, hospitals, or public safety systems, but may not capture broader economic impacts
The Iberian power grid collapse demonstrated these measurement challenges perfectly. Initial consumer reports spiked dramatically, then collapsed to near zero, not because service was restored, but because users lost the ability to report outages entirely. One operator in Portugal, MEO, maintained service longer than its competitors, an early sign of what resilience looks like in practice.
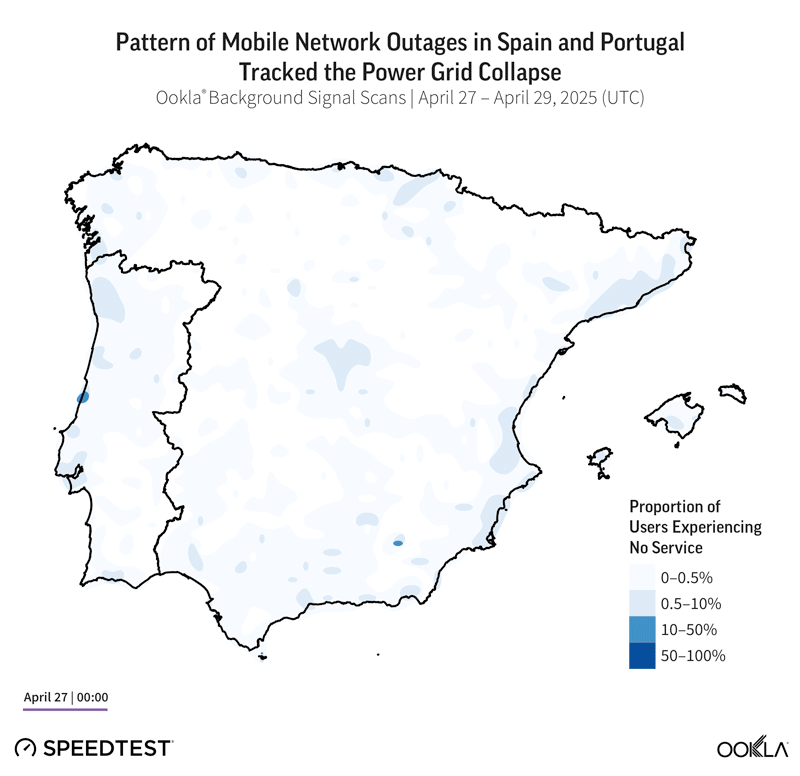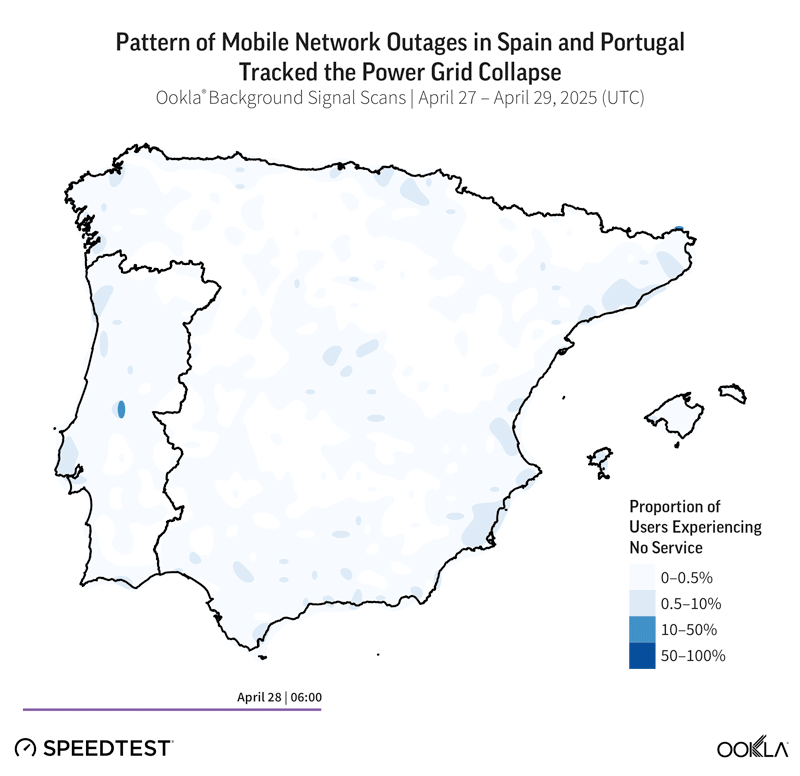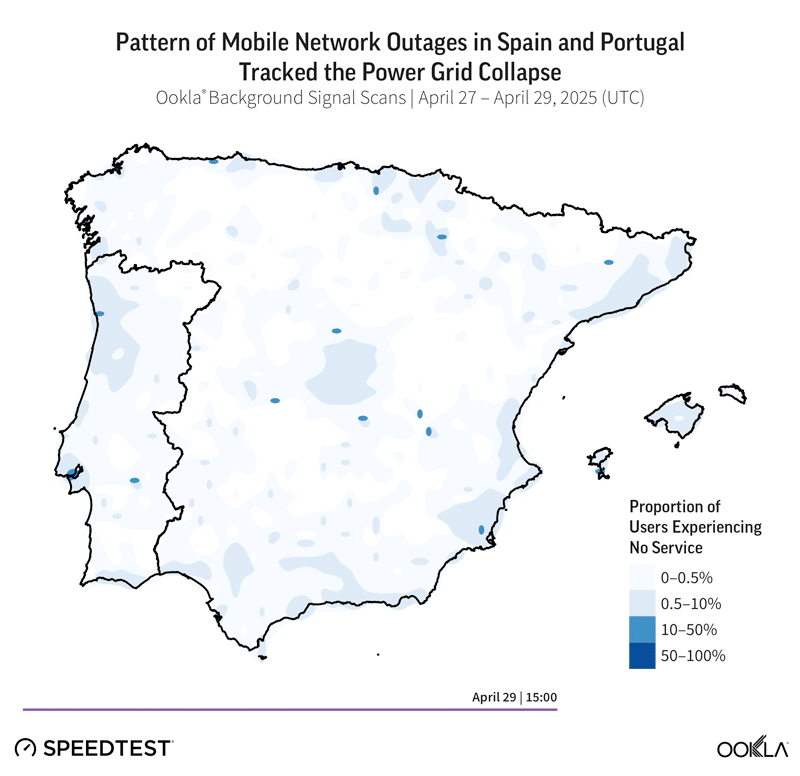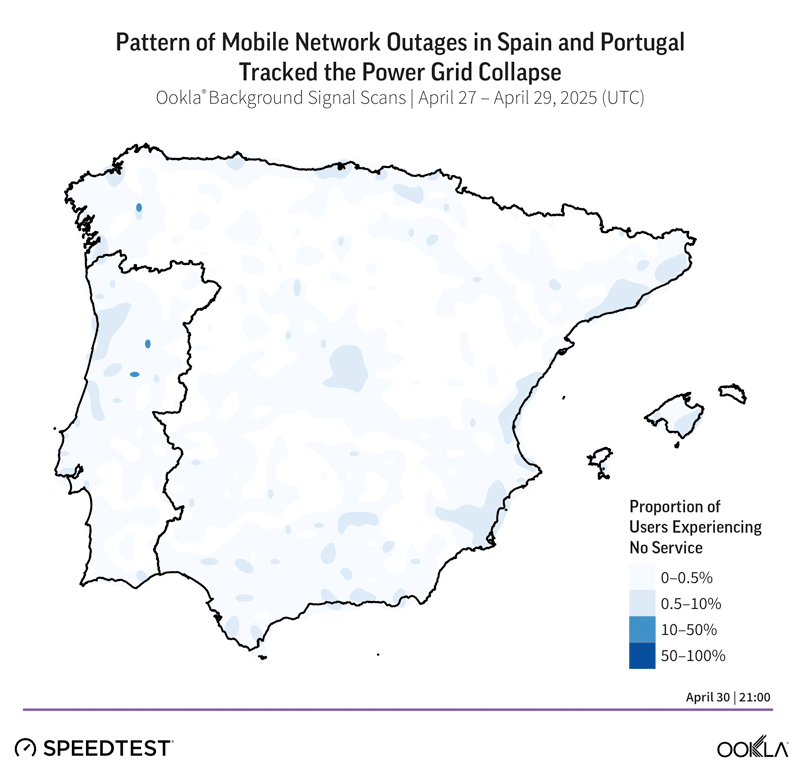
Analyzing Resilience: From Detection to to Communication to Learning
Major outages often unfold faster than anyone expects, and the difference between a temporary disruption and a systemic crisis lies in how effectively resilience is analyzed. In our recent webinar on network resilience, a practical framework was discussed that breaks resilience into five stages, each one critical to keeping disruptions from escalating:
- Detect: Spot the first signs of trouble across multiple data sources, from outage reports to operator dashboards
- Attribute: Identify the real root cause, whether it’s an internal software bug, an underwater cable cut, or a regional power failure
- Communicate: Share timely, accurate information with stakeholders and the public to reduce confusion
- Remediate: Act quickly to contain damage, restore critical services, and prevent cascading failures
- Learn: Capture lessons from the event and feed them back into playbooks, exercises, and long-term resilience planning
This framework underscores that resilience is not only about preventing outages; it’s also about building the capacity to respond, adapt, and improve when disruptions inevitably occur.
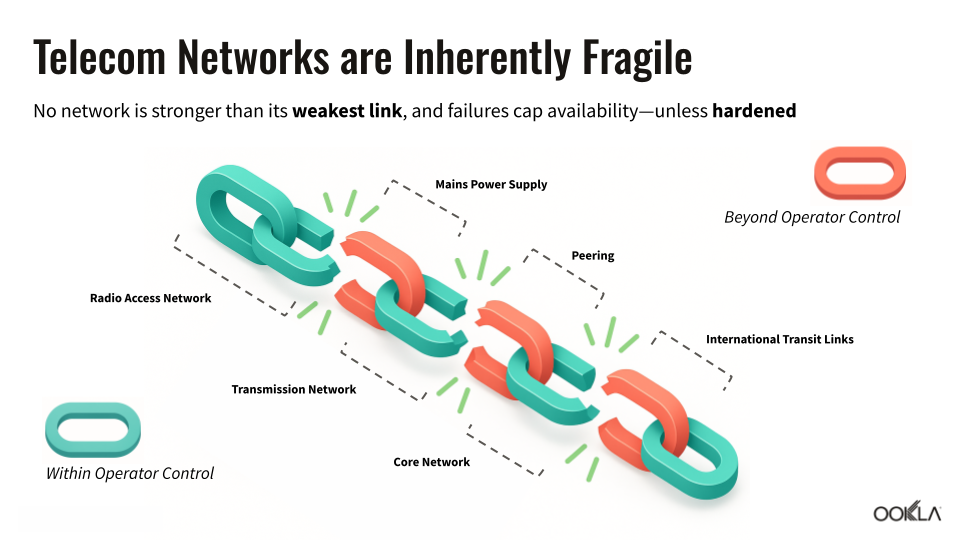
Power Dependencies: The Hidden Single Point of Failure
Power grids and mobile networks may look like separate systems, but major outages reveal how tightly connected they are. People often expect their phones to keep working in a crisis, yet service can disappear quickly once the electricity that powers cell sites and core facilities is lost.
Mobile networks are built with distributed architecture and multiple layers of redundancy, yet the April 2024 grid collapse exposed a fundamental vulnerability: dependence on external power. When regional electricity failed, mobile site failures moved in near-perfect lockstep with the power grid collapse, leaving over half of subscribers without service in affected areas.
The outage revealed dramatic differences in operator preparedness strategies and their real-world impacts:
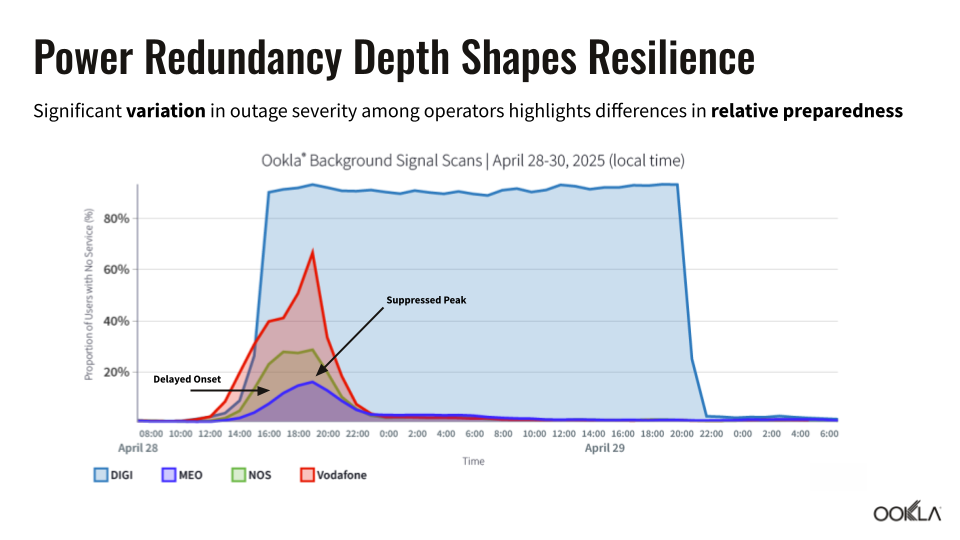
- Battery deployment depth: Portuguese operator MEO’s extensive battery investments created a “flattened outage curve”—service degradation began later and peaked lower than competitors, buying critical time for restoration efforts
- Core network protection: MEO maintained core network stability throughout the crisis, preventing a total service collapse that would have affected all subscribers simultaneously by investing in multi-day power autonomy
- Geographic redundancy: One competitor with centralized core infrastructure and a lack of geo-redundancy and power resilience saw its entire subscriber base go offline when its main facility in Lisbon lost power
- Backup power at cell sites: MEO’s six-hour battery capacity at most mobile sites provided meaningful service continuity, while some competitors with minimal backup power saw more immediate failures
During the crisis, roaming traffic on MEO’s network increased threefold as subscribers from failed networks automatically switched to available alternatives. MEO’s battery investments prevented total network collapse and provided backup connectivity for competitors’ customers during the extended outage.
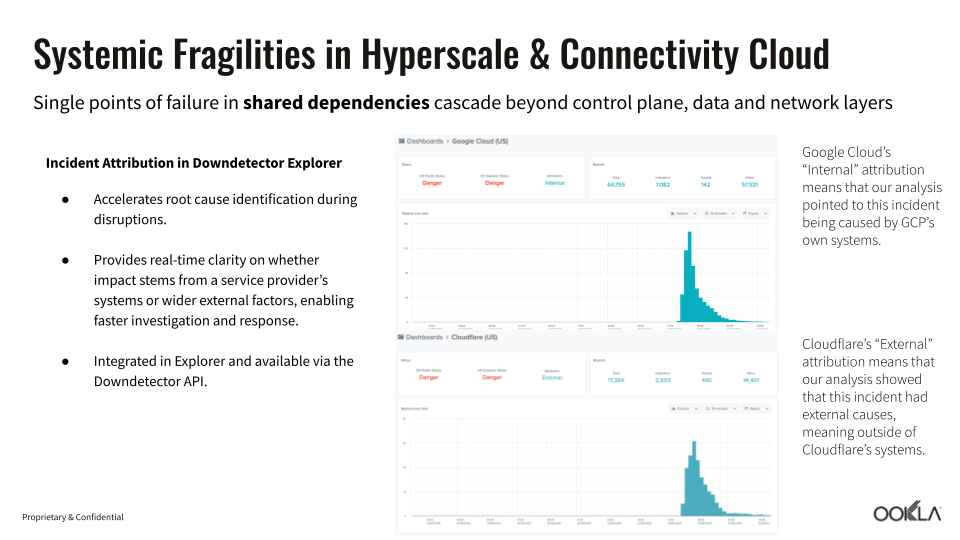
Cascade Effects: How Failures Multiply Across Digital Infrastructure
Apps and services may seem independent, but they often share hidden connections through common cloud platforms, authentication systems, or payment providers. Single points of failure in shared infrastructure can trigger cascading outages that extend far beyond the original problem. Cloud platform outages demonstrate how interconnected modern digital services have become, with failures at major providers like Google Cloud Platform and CloudFlare affecting thousands of downstream applications and services.
Recent cloud incidents reveal several common failure patterns that amplify initial problems:
- Management system failures: Many big cloud outages don’t come from the servers themselves going dark, but from the control systems that keep everything running. When those fail, it can knock out multiple services at once across different regions
- When one outage triggers others: Services like Spotify and Snapchat, which rely on Google Cloud infrastructure, become unavailable during Google’s outages, even though their own systems function properly
- Misidentifying the cause: Initial incident reports often misidentify root causes, leading to delayed or misdirected response efforts until proper analysis reveals the true source
These interconnected failures show how cloud outages can rapidly spread beyond their original source. When critical shared infrastructure fails, the impact can multiply across all the services that depend on it.
Crisis Response: Building Effective First-Hour Playbooks
The difference between manageable incidents and prolonged outages often comes down to what happens in the first hour after problems begin. MEO’s response to the Portugal power grid failure demonstrates how preparation and automated systems enable rapid crisis management even during unprecedented events.
Effective incident response relies on several key components that must be tested and refined before emergencies occur:
- Automated alerting and dashboards: MEO declared crisis status within 23 minutes of initial power grid failure because monitoring systems provided immediate impact assessment across fixed and mobile networks
- Regular disaster recovery exercises: Although the power grid scenario hadn’t been specifically tested, frequent tabletop and live exercises prepared response teams for rapid decision-making under pressure
- Prioritizing critical infrastructure: Maintaining stable core infrastructure prevented a total service collapse, allowing network-level management even as individual sites lost power
- Site-by-site damage assessment: Automated systems tracked how much backup power remained at each site, enabling strategic resource allocation during extended outages
MEO’s systematic approach during an unprecedented crisis shows that regular disaster exercises prepare teams for rapid decision-making when events turn out worse than expected. Even without testing the exact power grid failure scenario, MEO’s established processes enabled coordinated resource management under extreme pressure.
Policy Interventions That Drive Real Results
Effective resilience policies require more than regulatory requirements; they need funding mechanisms, technical standards, and international coordination to address the cross-border nature of modern digital infrastructure. Several countries have developed comprehensive approaches that combine multiple policy tools to improve network resilience outcomes, including Australia, Estonia, Finland, Colombia, and Japan.
Australia tackled resilience with a funding-first approach, using public investment to encourage operators to harden networks and explore new technologies:
- Direct infrastructure funding: Government programs support operators in deploying redundant infrastructure and network hardening measures that might otherwise be economically challenging
- Research and development support: Separate funding streams promote innovation in resilience technologies, from satellite backup systems to advanced battery technologies
- Geographic diversity requirements: Policies encourage infrastructure deployment in multiple regions to reduce single points of failure
In countries like Estonia, Finland, and Colombia, regulators have taken a mandate-driven approach, setting technical requirements operators must meet:
- Independent power source requirements: Regulations specify minimum battery backup duration and geographic coverage for critical network components
- Emergency power unit standards: Technical specifications ensure backup systems can actually maintain service during extended outages
- Essential component resilience: Regulatory standards in all three countries require critical network infrastructure to withstand specific types of disruptions (like extended power loss, physical damage, or cyber incidents)
Japan has focused on disaster preparedness, investing in satellite-based backup systems and supporting technologies suited to a country prone to earthquakes and severe weather:
- Satellite backup integration: Policies encourage operators to deploy satellite connectivity as a safeguard during large-scale disasters like earthquakes
- Targeted technology investment: Policymakers support research into backup solutions such as low Earth orbit (LEO) satellites, drones, and ships acting as base stations and alternative power systems to ensure continuity in disaster-prone regions
These examples show that there’s no single blueprint for resilience. Funding, mandates, and targeted technology programs can all play a role. What matters is aligning policy tools with national vulnerabilities, while recognizing that outages rarely stop at borders. The strongest results come when technical standards, public investment, and innovation work together to keep networks running through disruption.
Supply Chain Resilience: Managing Dependencies You Don’t Control
Supply chain resilience has become a pressing challenge as organizations move away from running every system in-house. With digital transformation, much of that control has shifted to cloud platforms, managed service providers, and software vendors. The change brings flexibility and scale, but it also creates a web of dependencies that are hard to map in normal times and nearly impossible to control during a major outage.
Effective supply chain risk management requires systematic ways to understand and manage the dependencies created by cloud providers, managed services, and third-party software vendors:
- Due diligence frameworks: Organizations must assess cybersecurity practices, business continuity plans, and resilience capabilities of critical suppliers before committing to rely on them
- Contractual accountability measures: Service level agreements (SLAs) need specific resilience metrics and clear remediation requirements, not just general availability targets
- Ongoing measurement and monitoring: Organizations should regularly assess supplier performance against agreed standards, including tests of backup procedures and incident response capabilities
- Cascading requirements: Suppliers should demonstrate that they hold their own critical vendors to the same resilience standards, extending accountability throughout the supply chain
During the CrowdStrike incident, affected organizations couldn’t simply point to their software vendor; instead, they had to manage customer impacts even though the root cause was completely outside their control. Modern supply chain resilience requires organizations to plan for failures in dependencies they cannot directly control while maintaining clear accountability for service delivery.
Building Networks That Bend Without Breaking
Network resilience has evolved from an operational concern to a strategic imperative that affects entire economies and societies. Recent major outages, whether caused by power grid failures or software incidents, show that traditional approaches centered on individual network components often fail to capture the systemic nature of modern digital infrastructure.
Building true resilience means preparing for failures across every layer of dependency, including power grids, software supply chains, and international infrastructure connections. The most effective strategies combine technical investments, policy frameworks, and organizational preparation. MEO’s performance during the Iberian power crisis illustrates how battery deployment and core network protection can reduce impacts, while national policies that pair funding, standards, and international coordination address challenges no single operator can solve alone.
Future resilience will depend on recognizing that no organization controls every factor affecting service reliability. Networks that bend without breaking require preparation, investment, and coordination, and recent events show these efforts can sharply reduce the human and economic costs when disruptions inevitably occur.

To explore the economic and operational stakes of major disruptions, read our white paper, The Cost of Downtime: A Guide to Proactive Outage Management. And for strategies organizations are using to improve resilience, watch our on-demand webinar, Navigating Disruption: Best Practices for Resilient Digital Infrastructure.
Ookla retains ownership of this article including all of the intellectual property rights, data, content graphs and analysis. This article may not be quoted, reproduced, distributed or published for any commercial purpose without prior consent. Members of the press and others using the findings in this article for non-commercial purposes are welcome to publicly share and link to report information with attribution to Ookla.
